本节详细说明一下最新GPU深度学习平台环境配置
Ubuntu16+RTX2080Ti+CUDA10.0+Anaconda3+Python3.6+Tensorflow1.13.1+Pytorch1.3.0
服务器环境
Ubuntu: 16.04 64bit
Nvidia driver 410
Anaconda: 3
python3.6
CUDA: 10.0
cuDNN: 7.4值得注意:如果您在RTX2080Ti环境下安装了CUDA10.0,GPU版Pytorch 最低只能安装1.2.0这个版本,TF也有相应的版本限制,请参考文末链接查看,考虑后再决定安装CUDA版本。如果先安装了CUDA10.0及10.0以上版本,而之后想使用低版本的Pytorch、TF,您可能需要降低CUDA至9.2版本✅,可考虑深度学习 环境配置(Tensorflow,Pytorch)多版本CUDA共存,请自行百度。
1.安装Linux系统
需要从网上下载ubuntu系统,并制作安装U盘。
- 准备工作。制作Ubuntu系统启动U盘,可参考链接
- U盘启动安装,开机按delete或f2进入BIOS,更改启动方式,U盘启动
- 进入ubuntun选择试用不安装,进入之前的unbuntun系统,备份home盘数据(如果不备份,重装系统数据会清除)。
- U盘启动,选择install unbuntun. 选择英文,图形界面不勾选,installtion type 选择 something else。 注:如果是安装双系统,不要选择第二项 擦除数据,这会把之前系统盘文件全部删除。
参考博客https://blog.csdn.net/fesdgasdgasdg/article/details/54183577?tdsourcetag=s_pcqq_aiomsg - 进入unbuntun系统,图形分辨率字很大,不用担心,因为没安装显卡驱动原因。
安装对应显卡驱动 - 安装完显卡驱动,你将拥有全新的unbuntun系统,则可以进行你常用的环境配置与软件安装,以自身需求,介绍一下要用到的深度学习环境和常用软件安装。安装常用软件 谷歌浏览器,搜狗输入法,notepad++, 为知笔记,pycharm, anaconda, cuda,opencv pytorch tensorflow 配置VPN,teamviewer 等。
cuda+cudnn,参考链接https://blog.csdn.net/gdengden/article/details/89399653
奇葩的问题:Ubuntu16.04 命令行 sudo:无法解析主机
在使用linux的sudo命令时候可能有些人会遇到这样的问题:“sudo:无法解析主机:xxxxx(您的主机名),遇到了这种问题,解决方案:
出现这种问题是hosts文件没有配置好所导致的,linux无法解析到您的主机地址,解决方案如下:
$ sudo vim /etc/hosts打开文件以后,将其中的 :
127.0.1.1 xxxxx后面的xxxx替换为你的电脑主机名字,也就是错误中最后那串字符。如果没有的话就将其添加进去。
可以在终端查看主机名:
$ hostname将查看的主机名代替xxxx即可。
- 利用lspic命令行工具便可用来获取显卡的硬件信息:
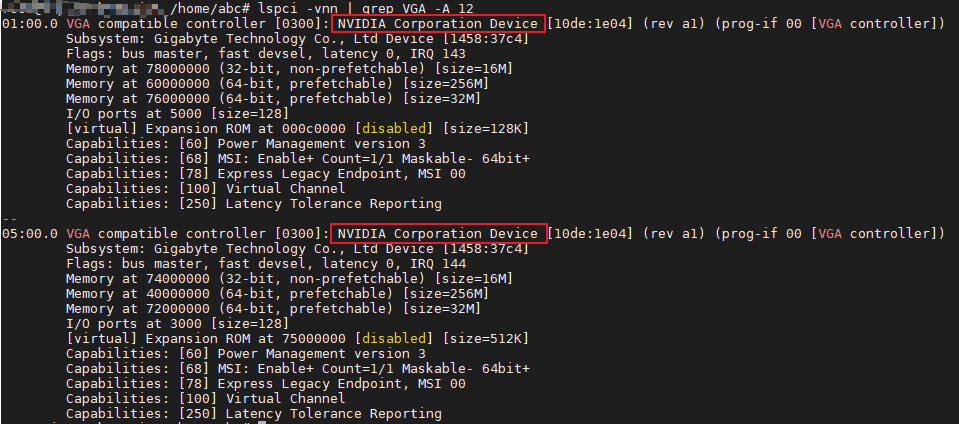
- 查看当前使用的显卡驱动

- 实际上我们则可以使用如下命令来检查显卡驱动的详情:
modinfo nvidia2.安装英伟达NVIDIA驱动
1.查看机器是否已经自带有其他显卡驱动
lshw -c video 或者 lshw -C display # 看configurure字段有木有driver字样,若有内容,则表示对应的工作站已经有显卡驱动了
sudo lshw -c video | grep configuration # 查看当前 Linux 系统上所使用的显卡驱动名称
注意!!! Ubuntu18.04 或者其它很有可能是configurure字段显示nouveau,而深度学习要用到NVIDIA驱动,所以先禁用nouveau;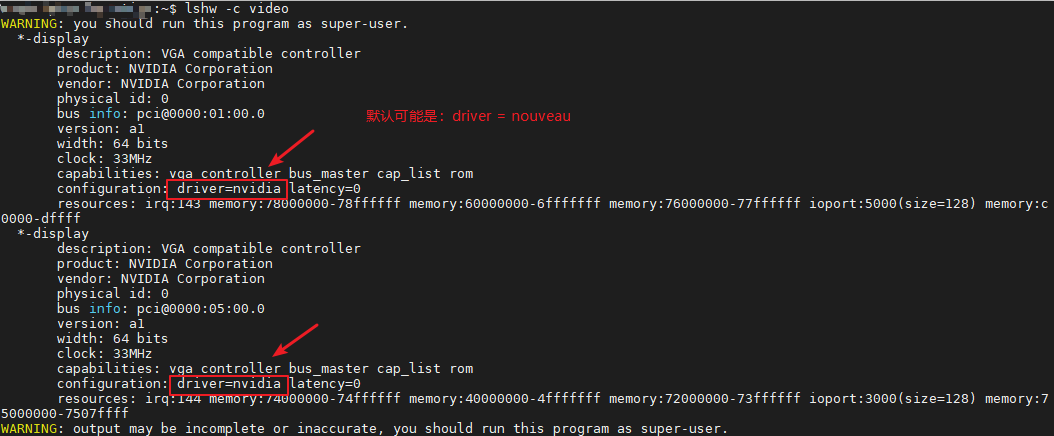
2.禁用自带的nouveau驱动(如果:configuration字段driver=nouveau)
安装NVIDIA需要把系统自带的驱动禁用,打开文件:
sudo vim /etc/modprobe.d/blacklist.conf在文本最后添加以下内容:
blacklist nouveau
options nouveau modeset=0命令窗口会提示warning,忽略即可。保存退出,执行以下命令生效:
sudo update-initramfs -u重启后,执行以下命令:
lsmod | grep nouveau如果屏幕没有任何输出,说明禁用nouveau成功
3.下载驱动文件
注意: 此处驱动的安装也可以不安装,比如新购置的服务器,可采用: CUDA+驱动同时安装 ,因为在安装CUDA时会提示你选择是否安装 合适的显卡驱动, 如果已经在此步骤安装过驱动了, 则可以在安装CUDA时把驱动安装取消选择即可
安装好linux系统后,对于RTX2080ti来说,Nvidia driver 384已经不适合了,请从官方网站下载和自己的显卡适配的驱动文件,是.run文件,下载地址: Download Drivers
下载完成之后会得到一个安装包,不同版本文件名可能不一样:
NVIDIA-Linux-x86_64-410.93.run4.卸载原有的NVIDIA驱动(没装的话就跳过第3步)
操作都需要在命令界面操作,执行以下快捷键进入命令界面,并登录:
Ctrl-Alt+F1执行以下命令禁用X-Window服务,否则无法安装显卡驱动:
sudo service lightdm stop执行以下三条命令卸载原有显卡驱动:
注意: 这里默认利用 runfile安装,卸载也需要这个runfile,所以安装完驱动最好保留之前的安装包,以备卸载的需要 ,参考: 安装驱动方式的不同,卸载也有些许不同
sudo apt-get remove --purge nvidia*
sudo chmod +x NVIDIA-Linux-x86_64-410.93.run
sudo ./NVIDIA-Linux-x86_64-410.93.run --uninstall5.安装新驱动
直接执行驱动文件即可安装新驱动,一直默认即可:
sudo ./NVIDIA-Linux-x86_64-410.93.run执行以下命令启动X-Window服务:
sudo service lightdm start最后执行重启命令,重启系统即可:
reboot安装完成后,查看驱动版本:
sudo dpkg --list | grep nvidia-*
nvidia-smi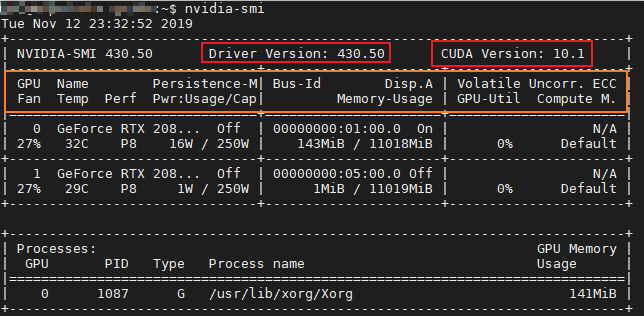
不出意外说明显卡驱动成功安装,后面继续安装cuda.
特别注意:如果系统重启之后出现重复登录的情况,多数情况下都是安装了错误版本的显卡驱动。需要下载对应本身机器安装的显卡版本。
上图是服务器上 GeForce RTX 2080 Ti 的信息,下面一一解读参数。
上面的表格中的红褐色框中的信息与下面的二个框的信息是一一对应的:
GPU:GPU 编号;
Name:GPU 型号;
Persistence-M:持续模式的状态。持续模式虽然耗能大,但是在新的GPU应用启动时,花费的时间更少,这里显示的是off的状态;
Fan:风扇转速,从0到100%之间变动;
Temp:温度,单位是摄氏度;
Perf:性能状态,从P0到P12,P0表示最大性能,P12表示状态最小性能(即 GPU 未工作时为P0,达到最大工作限度时为P12)。
Pwr:Usage/Cap:能耗;
Memory Usage:显存使用率;
Bus-Id:涉及GPU总线的东西,domain:bus:device.function;
Disp.A:Display Active,表示GPU的显示是否初始化;
Volatile GPU-Util:浮动的GPU利用率;
Uncorr. ECC:Error Correcting Code,错误检查与纠正;
Compute M:compute mode,计算模式。
下方的 Processes 表示每个进程对 GPU 的显存使用率。利用命令:nvidia-smi -L : 用于列出所有可用的 NVIDIA 设备信息

3.安装CUDA10.0
1.卸载旧的CUDA
这是因为如果您的显卡RTX2080,安装了CUDA 8.0 和 CUDNN 7.0.5或者CUDA9.0不能够正常使用,需要安装CUDA9.2或CUDA 10.0 和 cuDNN 7.4.2,所以要先卸载原来旧的CUDA。注意以下的命令都是在root用户下操作的。
卸载CUDA很简单,主要执行的是CUDA自带的卸载脚本,请根据自己的cuda版本找到卸载脚本:
如果之前安装了CUDA 9.0在 /usr/local/cuda-9.0/bin 目录下有一个 uninstall_cuda*.pl 文件,CUDA8卸载同理,可以直接运行卸载,命令如下:
sudo /usr/local/cuda-9.0/bin/uninstall_cuda_9.0.pl卸载之后,还有一些残留的文件夹,如果之前安装的是CUDA 9.0,可以一并删除:
sudo rm -r /usr/local/cuda-9.0/这样即可将 CUDA 全部卸载。
2.安装CUDA
安装的CUDA10.0和CUDNN7.4.2版本:
接下来的安装步骤都是在root用户下操作的。
- 下载和安装CUDA
我们可以在官网:CUDA10下载页面,
下面以CUDA10.0为例,安装时只需替换相应版本信息,请大家下载符合自己系统版本的CUDA!!!。
cd 到下载的文件目录.run文件下,root下安装
sudo chmod +x cuda_10.0.130_410.48_linux.run // 获取权限
sudo sh cuda_10.0.130_410.48_linux.run // 执行安装包,开始安装开始安装之后,需要阅读说明,可以使用Ctrl + C直接阅读完成,或者使用空格键慢慢阅读。然后进行配置,这里说明一下:
注意:为了避免问题,不要选择安装CUDA下的显卡驱动,其他选yes
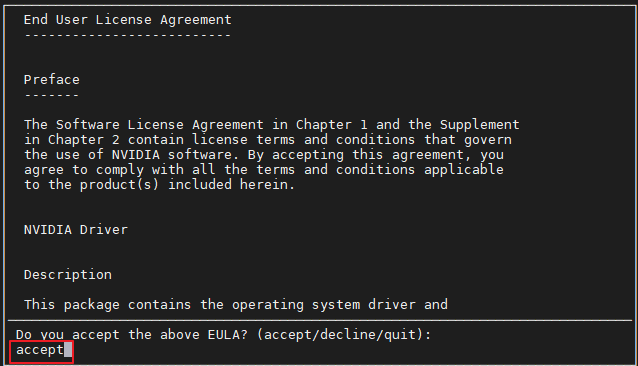
(是否同意条款,必须同意才能继续安装)
accept/decline/quit: accept
(这里不要安装驱动,因为已经安装最新的驱动了,否则可能会安装旧版本的显卡驱动,导致重复登录的情况)
Install NVIDIA Accelerated Graphics Driver for Linux-x86_64 410.48?
(y)es/(n)o/(q)uit: n
Install the CUDA 10.0 Toolkit?(是否安装CUDA 10 ,这里必须要安装)
(y)es/(n)o/(q)uit: y
Enter Toolkit Location(安装路径,使用默认,直接回车就行)
[ default is /usr/local/cuda-10.0 ]:
Do you want to install a symbolic link at /usr/local/cuda?(同意创建软链接)
(y)es/(n)o/(q)uit: y
Install the CUDA 10.0 Samples?(不用安装测试,本身就有了)
(y)es/(n)o/(q)uit: n
Installing the CUDA Toolkit in /usr/local/cuda-10.0 ...(开始安装)
cuda_10.1.105_418.39_linux.run 安装界面略有不同,安装界面如下:
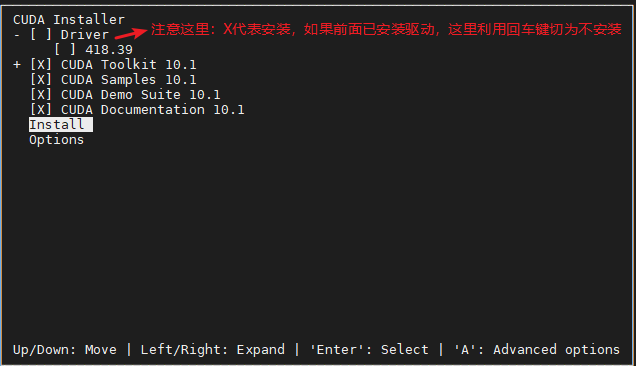
安装过程中,驱动前面已经安装,就不需要了,其他的默认安装,选择Install,回车,等待安装完成。请注意,X 表示安装,空表示不安装。
安装完成之后,可以配置他们的环境变量,打开.bashrc 文件:
sudo gedit ~/.bashrc打开文件后将下面代码加入文件最后,cuda位置,要根据自己cuda版本安装路径:
export CUDA_HOME=/usr/local/cuda
export LD_LIBRARY_PATH=${CUDA_HOME}/lib64:${LD_LIBRARY_PATH:+:${LD_LIBRARY_PATH}}
export PATH=${CUDA_HOME}/bin:${PATH}保存并关闭,命令行输入下面命令,使配置生效:
source ~/.bashrc终端输入:
nvcc --version 或 nvcc -V # 可以看到已经安装成功CUDA10版本了
会输出CUDA的版本信息,cuda安装成功。
4.下载和安装cuDNN
1.官网下载:https://developer.nvidia.com/rdp/cudnn-download
进入时需要登录,没有账户的话就注册一个,进入即可。选择和自己cuda适配的版本。
2.解压下载好的cudnn压缩包,如:
cudnn-10.0-linux-x64-v7.4.2.24.tgz 或者 cudnn-10.0-linux_x64-v7.6.0.64.tgz
tar -zxvf cudnn-10.0-linux-x64-v7.4.2.24.tgz 解压之后可以得到以下文件:
cuda/include/cudnn.h
cuda/NVIDIA_SLA_cuDNN_Support.txt
cuda/lib64/libcudnn.so
cuda/lib64/libcudnn.so.7
cuda/lib64/libcudnn.so.7.4.2
cuda/lib64/libcudnn_static.a使用以下命令复制这些文件到CUDA目录下:
#cp是copy指令
sudo cp cuda/include/cudnn.h /usr/local/cuda-10.0/include/
sudo cp cuda/lib64/libcudnn* /usr/local/cuda-10.0/lib64/
#chmod命令用于改变linux系统文件或目录的访问权限。
#a :所有的用户及群组。r :读权限。所以a+r表示所有用户都只有可读权限
sudo chmod a+r /usr/local/cuda-10.0/include/cudnn.h
sudo chmod a+r /usr/local/cuda-10.0/lib64/libcudnn*3.查看cudnn版本,可以使用以下命令查看CUDNN的版本信息
cat /usr/local/cuda/include/cudnn.h | grep CUDNN_MAJOR -A 2
安装好cuda和cudnn之后,恭喜你,就可以安装tensorflow、pytorch等深度学习框架了。
5.安装Anaconda3
这里使用 Anaconda 3 来安装,下载地址:https://www.anaconda.com/download/#linux,点击 Download 按钮下载即可,这里下载的是 Anaconda 3-5.1 版本,如果下载速度过慢,强烈建议选择使用清华镜像 。
下载下来之后目录下会出现一个 Anaconda3-5.1.0-Linux-x86_64.sh 文件,然后直接执行即可安装:
bash Anaconda3-5.1.0-Linux-x86_64.sh执行完毕之后按照默认设置走下来即可完成安装。
这里默认它会安装到用户目录下,如果想全局安装,可以在这一步输入你要安装的地址:
Anaconda3 will now be installed into this location:
/home/wy/anaconda3
- Press ENTER to confirm the location
- Press CTRL-C to abort the installation
- Or specify a different location below
[/home/wy/anaconda3] >>> /usr/local/anaconda3
PREFIX=/usr/local/anaconda3这里我指定了将其安装到 /usr/local/anaconda3 目录下,全局安装,所有用户共享,当然如果只想本用户使用的话使用默认配置即可。
安装完成之后添加 python3 和 pip3 的软链接:
sudo ln -s /usr/local/anaconda3/bin/python3 /usr/local/sbin/python3
sudo ln -s /usr/local/anaconda3/bin/pip /usr/local/sbin/pip3这里是将软连接其添加到 /usr/local/sbin 目录下了,它默认会存在于环境变量中,因此可以直接调用。
当然也可以选择把 /usr/local/anaconda3/bin 目录添加到环境变量中,具体地,可以修改 ~/.bashrc 文件,添加如下内容:
export PATH=/usr/local/anaconda3/bin${PATH:+:${PATH}}然后执行:
source ~/.bashrc即可生效,下次登录时也会默认执行 ~/.bashrc 文件,也会生效。
接下来我们验证下 python3、pip3 命令是否都来自 Anaconda,命令如下:
pip3 -V
pip 9.0.1 from /usr/local/anaconda3/lib/python3.6/site-packages (python 3.6)which python3
/usr/local/anaconda3/bin/python3
python3
Python 3.6.4 |Anaconda, Inc.| (default, Jan 16 2018, 18:10:19)
[GCC 7.2.0] on linux
Type "help", "copyright", "credits" or "license" for more information.
>>>如果输入 pip3 和 python3 命令能出现如上类似结果,路径都在 /usr/local/anaconda3,就证明 Python 3 安装成功了。
总结上面步骤,安装好CUDA、cuDNN、Anaconda后关键做到的两点:
1、进入root用户,在root下配置环境变量,更新配置文件
su root
cd
Enter # 回车
gedit .bashrc
# 在文件末尾添加环境变量
export PATH=/usr/local/anaconda3/bin${PATH:+:${PATH}}
export CUDA_HOME=/usr/local/cuda
export LD_LIBRARY_PATH=${CUDA_HOME}/lib64:${LD_LIBRARY_PATH:+:${LD_LIBRARY_PATH}}
export PATH=${CUDA_HOME}/bin:${PATH}
# 保存退出
# 更新配置文件
source .bashrc2、然后配置普通用户的环境变量
su 普通用户名
cd
Enter # 回车
gedit .bashrc
# 在文件末尾添加环境变量
export PATH=/usr/local/anaconda3/bin${PATH:+:${PATH}}
export CUDA_HOME=/usr/local/cuda
export LD_LIBRARY_PATH=${CUDA_HOME}/lib64:${LD_LIBRARY_PATH:+:${LD_LIBRARY_PATH}}
export PATH=${CUDA_HOME}/bin:${PATH}
# 保存退出
# 更新配置文件
source .bashrc特别说明:本文只针对单用户GPU环境及软件安装做了详细说明,如果是多个用户在一台多显卡服务器上作开发,则需要利用conda进行python虚拟环境的创建与管理,所以需要各个用户在自己的账户下独立安装Anaconda,并在当前用户中的.bashrc文件中将Anaconda路径改为本用户下安装的Anaconda路径,而不是root用户中的Anaconda路径。
6.安装TensorFlow 1.13.1
到现在为止 Python 3.6、CUDA 10.0 和 cuDNN 7.14就已经安装好了,而且环境变量也配置好了,接下来我们直接安装 TensorFlow 1.13.1 即可。
这里需要安装的是 TensorFlow 的 GPU 版本,命令如下:
pip3 install tensorflow-gpu==1.13.1你会发现上面安装特别慢,强烈建议使用 国内pypi源加速 , 速度超快啊!!!
pip3 install tensorflow-gpu==1.13.1 -i https://pypi.tuna.tsinghua.edu.cn/simple安装完成之后验证一下:
python
import tensorflow as tf
tf.__version__
tf.__path__如果没有报错,那就证明全部环境配置都成功了。
如果报错:
FutureWarning: Conversion of the second argument of issubdtype from `float` to `np.floating` is deprecated. In future, it will be treated as `np.float64 == np.dtype(float).type`.
from ._conv import register_converters as _register_converters报错原因: 因为你所使用的h5py库,有一部分函数与numpy1.14有冲突
解决方法: 对h5py库进行升级 ✅
pip3 install h5py==2.8.0rc1 -i https://pypi.tuna.tsinghua.edu.cn/simple如果您的tensorflow安装后不能使用,请参照官方安装手册:tensorflow版本和CUDA、cuDNN版本的兼容问题, 也可参考本博文下方链接。
7.Pytorch 1.3.0
7.1 安装过程中注意:torch和torchvision版本必须相匹配
如不匹配,可能报错:
torchvision 0.3.0 has requirement torch>=1.1.0, but you'll have torch 1.0.0 which is incompatible.RTX 2080Ti,CUDA安装版本10及以上,
方案一: 通过pytorch官发链接pip装,命令如下:
pip3 install https://download.pytorch.org/whl/cu100/torch-1.1.0-cp36-cp36m-linux_x86_64.whl发现速度实在太慢!!于是我们考虑
方案二: 离线安装:
注意方案一 在控制台出现的下载路径,复制到浏览器,手动下载:
到官网下载torch1.1:https://download.pytorch.org/whl/cu100/torch-1.1.0-cp36-cp36m-linux_x86_64.whl ,将本地文件上传到服务器指定位置,路径换到压缩包所在位置,在控制台输入指令:
pip3 install torch-1.1.0-cp36-cp36m-linux_x86_64.whl
pip3 install torchvision==0.3.0方案三: 以上两种方案纯属呵呵🙂,强烈建议使用 国内pypi源加速 , 直接安装pytorch最新版本,最新版本做了诸多优化!通过pypi镜像安装速度超快啊 ★★★★★ 👍👍👍
pip3 install torch torchvision -i https://pypi.tuna.tsinghua.edu.cn/simple这样就安装好啦,然后测试一下, 会输出torch版本1.3.0,torchvision版本0.4.1:
python
import torch,torchvision
torch.__version__
torchvision.__version__
torch.__path__
torchvision.__path__7.2 GPU 测试失败原因
按照以上教程走完安装过程测试,出现如下情况
>>> python
>>> import torch
>>> torch.cuda.is_available()
False找到原因:
显卡驱动太老,解决办法:替换原有驱动。查看驱动对应的cuda的型号 nvcc --version
参考链接:
nvidia与cuda需要满足关系:
https://docs.nvidia.com/cuda/cuda-toolkit-release-notes/index.html
cuda与cudnn需要满足关系:
https://developer.nvidia.com/rdp/cudnn-archive查看torch的对应cuda的版本
>>> python
>>> import torch
>>> print(torch.version.cuda)注意: 在CUDA10.0 安装了 torch版本1.1.0和torchvision版本0.3.0,当你运行程序很可能会报错:
RuntimeError: cuda runtime error (11) : invalid argument at /pytorch/aten/src/THC/THCGeneral.cpp:383解决方法:升级torch版本到1.1.0以上即可解决!!!
7.3 关于使用PyTorch设置多线程(threads)进行数据读取而导致GPU显存始终不释放的问题
使用PyTorch设置多线程(threads)进行数据读取(DataLoader),其实是假的多线程,他是开了N个子进程(PID都连着)进行模拟多线程工作,所以你的程序跑完或者中途kill掉主进程的话,子进程的GPU显存并不会被释放,需要手动一个一个kill才行,具体方法描述如下:
1.先关闭ssh(或者shell)窗口,退出重新登录
2.查看运行在gpu上的所有程序:
fuser -v /dev/nvidia*3.kill掉所有(连号的)僵尸进程
以上便是 Ubuntu 16.04 + RTX 2080 Ti + Python 3.6 + CUDA 10.0 + cuDNN 7.4 + TensorFlow 1.13.1 + Pytorch 1.3.0等 完整环境配置过程。
8.配置 ssh 远程连接
1)安装 open-ssh
apt-get install openssh-server2)修改权限,允许 ssh 登录 root
gedit /etc/ssh/sshd_config注释 :PermitRootLogin prohibit-password
添加: PermitRootLogin yes
3)重启 ssh
service ssh restart9.Linux终端复用工具 Tmux
Tmux 的全称是 Terminal MUtipleXer,及终端复用软件。顾名思义,它的主要功能就是在你关闭终端窗口之后保持进程的运行,此外 Tmux 的另一个重大功能就是分屏 .
前言
很多时候我们需要通过SSH连接服务器进行一些操作,费了好长时间调好了程序,一顿饭的功夫SSH超时了(broken pipe),重新连上去正在运行的程序也都没了,一切又得从头再来。这个时候你就非常需要用到tmux了,用tmux在服务器上创建一个会话(Session),在该会话中进行操作,你可以随时随地断开和重新连接会话(Session),即便是SSH中断了你在远程服务器上的工作状态也可以持久化地保存。
安装及使用方法
Tmux结构
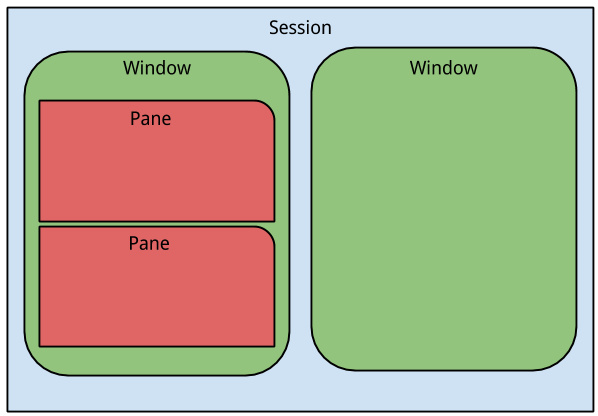
vim端
tmux new -s name 创建name
tmux attach -t name 重启name
tmux ls 列出所有session
tmux kill-server 删除所有session
tmux a 进入最近的会话
tmux a -t 会话名 进入指定会话
tumx kill-session -t 会话名 干掉指定会话
tmux中(命令前缀ctrl+b)
d 退出当前session
s 切换session
c 创建新窗口
0-9 切换指定窗口
w 窗口列表
% 竖直分屏
“ 左右分屏
x 关闭当前屏幕
10.Windows全能终端神器MobaXterm安装
主要功能](https://mobaxterm.mobatek.net/):
支持各种连接SSH,X11,RDP,VNC,FTP,MOSH
支持Unix命令(bash,ls,cat,sed,grep,awk,rsync,…)
连接SSH终端后支持SFTP传输文件
各种丰富的插件(git/dig/aria2…)
可运行Windows或软件
注意:如果你想利用MobaXterm中的VNC可视化远程服务器窗口,方法有二:
方法一:Linux下开启VNCserver服务(非常不推荐 😪)
方法二:参考博文设置 (极力推荐!!! 😃)
11. No module named ‘cv2’等python库解决方法及Python包更新方法
只要是缺少的python库文件,请善用 国内pypi源加速 , 速度超快啊!!!
pip3 install opencv-python -i https://pypi.tuna.tsinghua.edu.cn/simple当你需要更新python包时,还是那句话,请善用 国内pypi源加速 , 速度超快啊!!!
如:我当前需要更新pip
pip install --upgrade pip -i https://pypi.tuna.tsinghua.edu.cn/simple



